¶ Datenmanagement
¶ ShareIt ERM
¶ Datenbanksysteme (DBS)
... dienen zur elektronischen Verwaltung von Daten und der Lösung von Problemen auf deklarativer Art. Zur Verwaltung gehören Speicherung, Bearbeitung und Ausgabe von Daten.
Um mit Daten zu arbeiten wird eine Datenbasis (DB, gesammelte und gespeicherten Daten) benötigt. Der Zugriff auf die DB erfolgt über das Datenbankmanagementsystem (DBMS).

¶ Vorteile
- Systematisch strukturierte Daten
- Langfristige Verfügbarkeit
- Gleichzeitiger Zugriff von verschiedenen Stellen aus
- Sotierung/Filtern
- Auswertung mittels Abfragen
- Berichte/Export
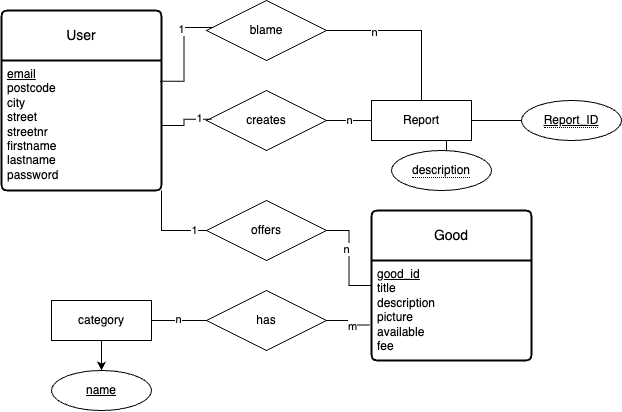
¶ Entity-Relationship-Modell
Ein Entity-Relationship-Modell ist eine Beschreibung der Datenwelt

¶ Primärschlüssel
Identifiziert eine Entität einer Entitätsmenge eindeutig und kann aus mehereren Schlüsselattributen zusammengesetzt werden.
¶ Übungen
Weitere Übungsaufgaben: Aufgaben
¶ Relationenmodell
Im Relationenmodell wird z.B. aus dem Entitytyp „Lehrer“ die Relation „Lehrer“. Eine Relation ist eine zweidimensionale Tabelle. Dargestellt werden die Daten in Form von Spalten = Attribute (1. Dimension) und Zeilen = Tupel/Daten (2. Dimension)

Beispiel

¶ Transformationsregeln
https://bildungu.eu/relationenmodell-rm/
¶ 1.Umwandlung von Entitätstypen
- jeder Entitytyp hat mindestens eine Relation
- Primärschlüssel übernehmen und unterstrichen
- jedes Attribut -> Spalte/Spaltenüberschrift
- alle Spaltenüberschriften zusammen ergeben das Relationsschema
- Beispiel
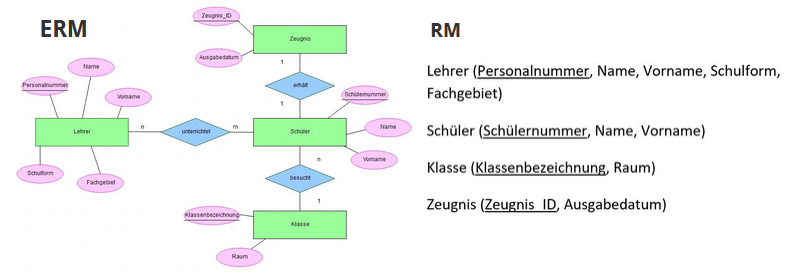
- Beispiel
¶ 2.Umwandlung einer 1:n Beziehung
- die Tabele der n-Seite der Beziehung erhält zusätzliches Attribut, welches den Zugehörigen Datensatzt der 1-Seite eindeutig festleget (Primärschlüssel)
- Die neuen Attribute nennt man Fremdschlüssel (FS)
- Beispiel
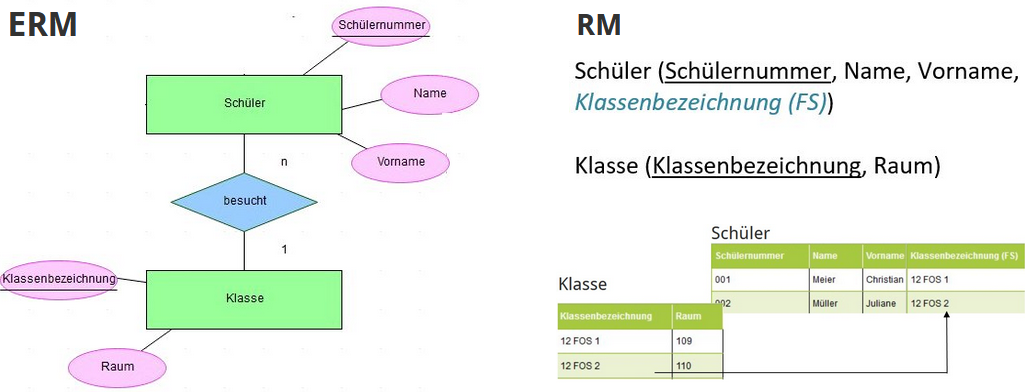
- Beispiel
¶ 3.Umwandlung einer 1:1 Beziehung
- zur Realisierung einer 1:1 Beziehung wird eine der beiden Entitätsmengen um den Primärschlüssel der anderen als Fremdschlüssel ergänzt
- Beispiel
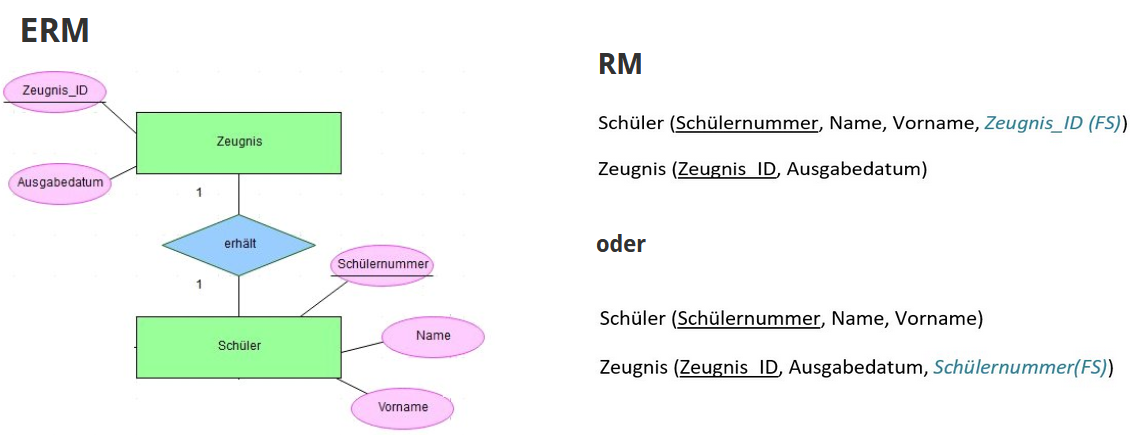
- Beispiel
¶ 4.Umwandlung einer n:m Beziehung
- Zur Realisierung einer n:m Beziehung muss eine weitere Tabelle angelegt werden. Diese trägt den Namen des dazugehörigen Relationshiptypen.
- Diese Tabelle enthält die Primärschlüssel der zu verknüpfenden Tabellen als Fremdschlüssel.
- Der Primärschlüssel der Tabelle ist die Kombination beider Fremdschlüssel.
- Hinweis: Jede Tabelle muss einen Primärschlüssel enthalten!
- Beispiel
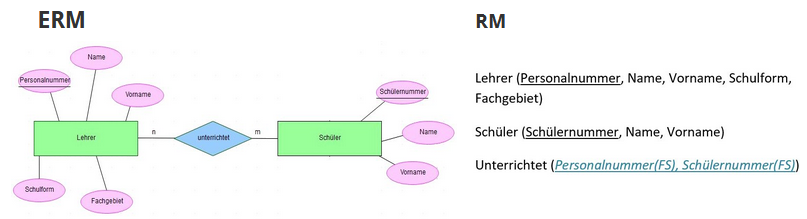
- Beispiel
¶ Beispiel Übungen
Überführe die folgenden ERMs in RMs
Beispiel 1
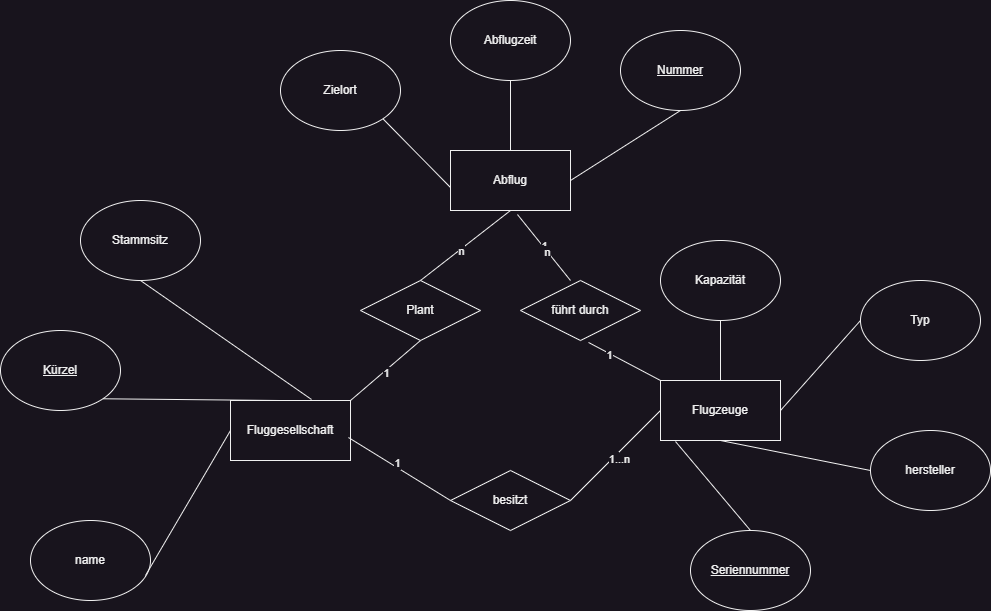
Dazu folgendes Relationsmodell:
Abflug(Nummer, Abflugzeit, Zielort,
Kürzel→, Seriennummer→)
Flugzeuge (Seriennummer, Hersteller, Typ, Kapazität,
Kürzel→)
Fluggesellschaft(Kürzel, Stammsitz, Name)
Pilot(Person_ID, Name, Alter)
Wird_geflogen (Seriennummer →, Person_ID →)
Beispiel 2
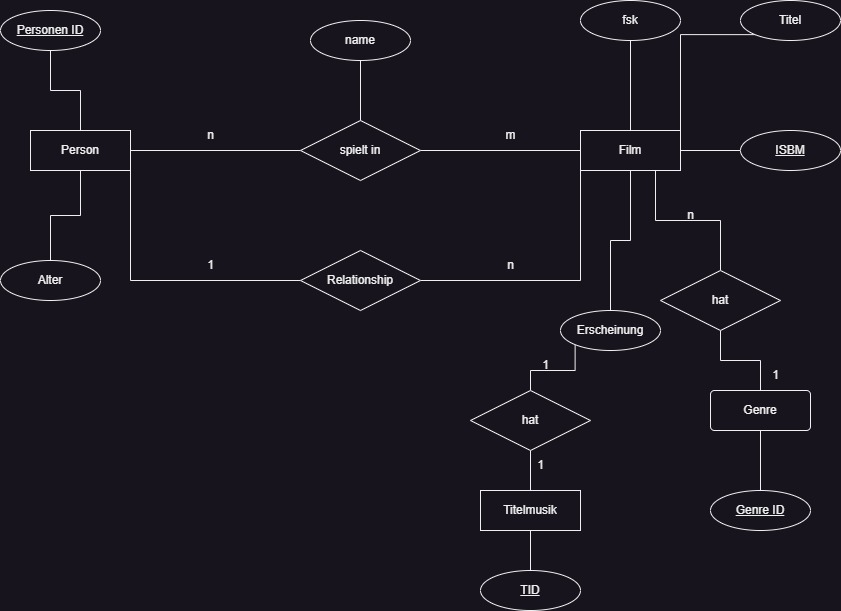
¶ Begriffserklärungen
¶ Redundanz
- Mehrfachspeicherung von Daten
- Vermeidung durch keine Dopplung von Daten
Nachteile:
- Überflüssiger Verbrauch von Speicherplatz
- Fehler im Datenbestand
¶ Anomalie
Es wird zwischen drei Arten der Anomalie unterschieden:
- Einfügeanomalie: Neue Daten können nicht eingefügt werden, ohne neue unnötige Daten anzugeben
- Änderungsanomalie: Änderungen an einem Datensatz müssen an mehreren Stellen durchgeführt werden
- Löschanomalie: Durch das Löschen eines Datensatzes gehen auch wichtige, andere Informationen verloren
¶ Inkonsistenz
- Unterschiedliche Werte für dasselbe Attribut an verschiedenen Stellen
- Entsteht häufig durch Redundanz und fehlende Synchronisierung von Daten
¶ Normalisierung und Normalformen
Normalisierung eines relationalen Datenbankmodells
= Aufteilung von Attributen in mehrere Relationen (Tabellen) mithilfe von Normalisierungsregeln in Normalformen, die keine vermeidbaren Redundanzen enthalten. (Quelle: https://www.datenbanken-verstehen.de/datenmodellierung/normalisierung/)
Übersicht Normalformen
| Normalform | Definition |
|---|---|
| 1 | Alle Attribute haben einen atomaren Wertebereich |
| 2 | 1. Normalform und jedes Nichtschlüsselattribut vom Primärschlüssel voll funktional abhängig ist und nicht bereits von einem Teil der Schlüsselattribute |
| 3 | 2. Normalform und kein Nichtschlüsselattribut gibt, das transitiv abhängig von einem Schlüsselattribut ist. Es darf damit keine funktionalen Abhängigkeiten zwischen Nichtschlüsselattributen geben. |
Gute Zusammenfassungen + Übungen
- Zusammenfassung
- hier zu Übungen
¶ SQL
SQL stands for “structured query language”. It is a language used to query, analyze, and manipulate data from databases. Today, SQL is one of the most widely used tools in da (Quelle: https://www.datacamp.com/cheat-sheet/sql-basics-cheat-sheet )
¶ Create Table
Erzeugt Tabelle
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);
Datentypen sind Integer, Text, Numeric, Real, Blob (je nach SQL-Dialect/DBMS gibt es auch andere)
Jeder Spalte können Constrains wie NotNull, Unique, PrimaryKey, AutoIncrement oder ForeignKey (Fremdschlüssel) hinzugefügt werden.
Beispiel
CREATE TABLE "Schueler" (
"id" INTEGER,
"firstname" TEXT,
"lastname" TEXT,
PRIMARY KEY("id" AUTOINCREMENT)
)
¶ Insert
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
Beispiel
INSERT INTO Schueler (firstname, lastname) VALUES ("Max","Mustermann");
¶ Select
Übungen mit Instahub mit folgendem ERM.
Instahub (admin/admin)
Übungen: uebungen_instahub.zip
¶ Lösung GroupBy
SELECT gender, COUNT(*) FROM users GROUP BY gender
SELECT gender, AVG(centimeters) FROM users GROUP BY gender
SELECT birthday, COUNT(*) AS ANZAHL FROM users GROUP BY birthday HAVING ANZAHL > 1
SELECT city, AVG(centimeters) AS groesse FROM users GROUP BY city HAVING groesse > 185
SELECT user_id, COUNT(*) FROM photos GROUP BY user_id
SELECT user_id, COUNT(*) AS Anzahl FROM photos GROUP BY user_id HAVING Anzahl > 13
CheatSheets
- SQL Basic Cheat Sheet von LearnSQL
- SQL Basic Cheat Sheet von datacamp
- SQL Cheat Sheet (zur Klausur zugelassen) von sqltutorial
¶ Datenlebenszyklus/ Data Life Cycle
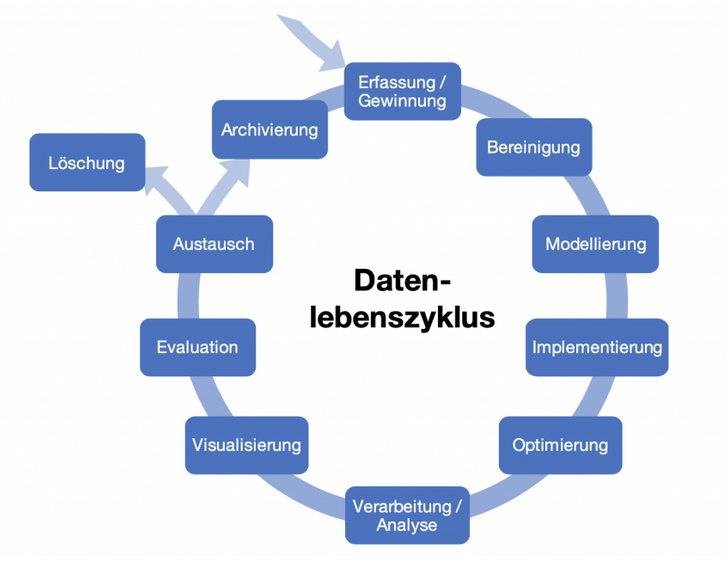
- Datenerfassung/-gewinnung
- Erfassung neuer Daten, beispielsweise mit Sensoren
- die Zugänglichmachung von Daten durch geeignete Strukturierung oder Konvertierung aus anderen Formaten
- Recherche nach und Abfrage von geeigneten bereits existierenden Datensätzen
- Gegebenenfalls können Daten mehrerer Quellen bereits an dieser Stelle zusammengeführt werden.
Zielgerichtete Datenerfassung:
Datenextraktion:
Datenbereinigung:
-
Datenbereinigung
- wird nötig, falls die vorliegenden Datensätze:
- ungültige (z. B. Auslesefehler von Daten eines Sensors oder Werte außerhalb des definierten/zulässigen Wertebereichs),
- falsche (z. B. erkennbare Messfehler)
- oder ungeeignet formatierte Daten (z. B. Datumsangaben als Klartext oder im falschen Format) enthalten
-> müssen gefiltert und/oder korrigiert werden
-
Modellierung
- Modellierung wird insbesondere zur klaren und verständlichen Strukturierung von Daten und zur Verdeutlichung von Zusammenhängen zwischen verschiedenen Datensätzen genutzt, aber auch um einen Überblick über bereits existierende Datensätze und deren Struktur zu bekommen.
-
Implementierung
- Die Implementierung des Datenmodells in einem realen Datenmanagementsystem ermöglicht die Nutzung und Speicherung von Daten und ist damit grundlegend für die folgenden Praktiken.
-
Optimierung
- umfasst beispielsweise die Anreicherung von Daten durch weitere, beschreibende Daten zur Erreichung eines schnelleren Zugriffs (z. B. Indizierung), die Kombination von Daten, aber auch alle anderen Ansätze, die darauf abzielen, die Speicherung von und den Zugriff auf Daten möglichst effizient zu gestalten.
-
Verarbeitung/Analyse
- umfasst insbesondere Aggregation von Daten
- aber auch die Erzeugung neuer Informationen aus Daten unter Nutzung verschiedener Datenanalysemethoden
-> zum Beispiel Clustering, Assoziation und Klassifikation.
-
Visualisierung
- Visualisierungstechniken werden genutzt, um die Analyseergebnisse verständlich und gut erfassbar für den Menschen aufzubereiten.
-
Evaluation
- umfasst, neben der Beurteilung der eigentlichen Ergebnisse, auch die Einschätzung der Qualität des ursprünglichen Datensatzes und des Analyseansatzes.
-
Austausch
- Teilen der Daten über verschiedene Wege
-
Löschung oder Archivierung
- Die Löschung der Daten kann aus verschiedenen Gründen erfolgen:
-> Löschung zur Gewinnung von Speicherplatz
-> Persönlichkeitsrecht von Personen zu wahren - Durch die (sichere) Löschung wird, im Gegensatz zur Archivierung, eine spätere Verwendung der Daten unterbunden.
- Die längerfristige Archivierung von Daten wird genutzt, um diese für zukünftige (oft noch nicht vorhersehbare) Zwecke zu nutzen.
- Durch die Archivierung wird die weitere Nutzung von Daten für eine gewisse Zeit unterbrochen, sie werden aber für mögliche spätere Nutzungen weiterhin vorgehalten.
- Die Löschung der Daten kann aus verschiedenen Gründen erfolgen:
¶ Datentyp
Der Begriff Datentyp bezeichnet eine Menge von Objekten, die alle die gleiche Struktur haben und mit denen die gleichen Operationen durchgeführt werden können.
Wichtige Datentypen:
- Gleitkommazahl (Float)
- Zeichenkette (String)
¶ Big Data
¶ Metadaten
Ein Datensatz enthält nicht nur die "gewollten" Daten, sondern auch Daten über sich selbst. Beispielsweise enthalten Fotos Daten über den Aufnahmeort, das Aufnahmedatum, die getätigten Einstellungen oder den Fotographen.
- Dienen zur:
-> Filterung und Suche
-> Organisierung
-> Datenanalyse - Jedoch besteht die Gefahr beim Hochladen von Daten, dass man ungewollt seine Metadaten mit veröffentlicht und somit ungewollt Informationen preisgibt
¶ Bias
Von einem Data Bias (Datenbias) sprechen wir, wenn Daten Verzerrungen aufweisen, nicht repräsentativ sind oder unbewusste Vorurteile widerspiegeln.