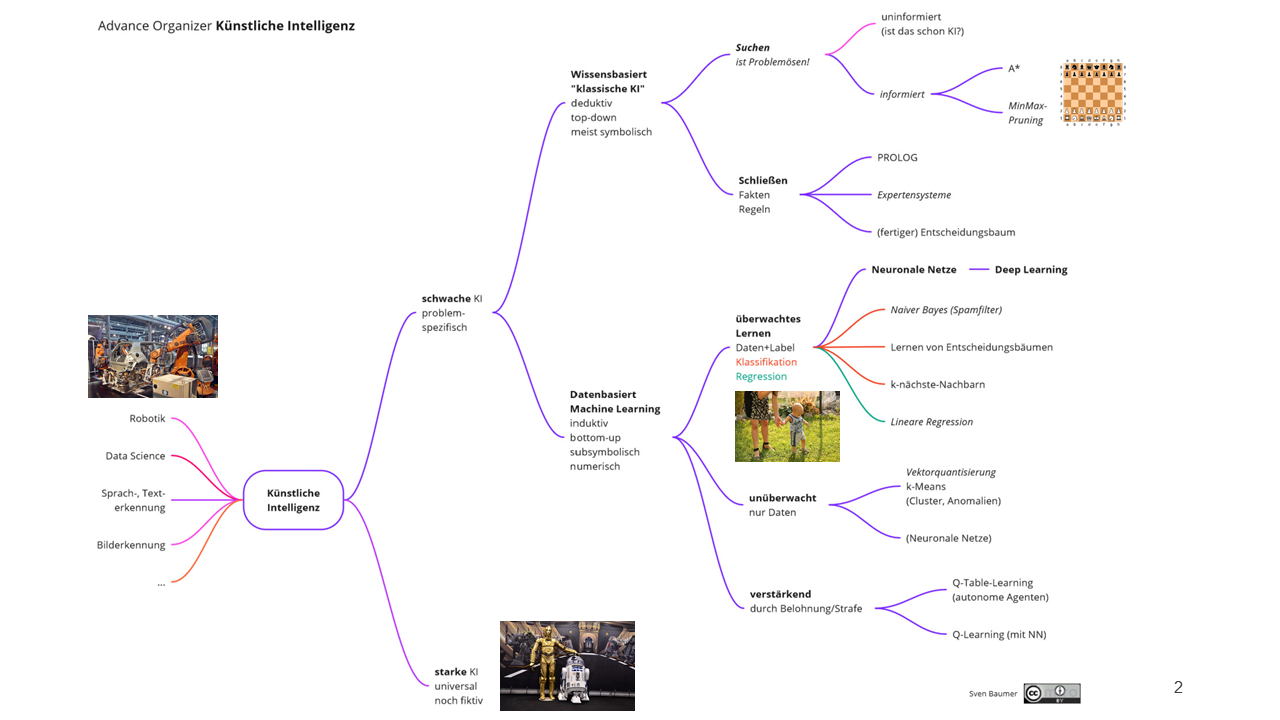
¶ Künstliche Intelligenz
¶ KI-Modelle
- HIER Drücken um zuden KI-Modellen zu kommen: HIER
¶ Was ist KI?
- KI ist eine Hilfeleistung der Menschen für die Lösung von Problemen
- Eine KI ist auf eine Aufgabe spezialisiert
- Jedoch schwer zu definieren, da es keine Wirkliche Definition für "Intelligenz" gibt
- Man unterscheidet zwischen Starker und Schwacher KI
¶ Starke vs. Schwache KI
| Starke KI | Schwache KI |
|---|---|
| Ist in der Lage menschliche Intelligenz zu Imitieren oder zu Überschreiten | Kann nur durch Menschen handeln |
| Kann sich selbst weiterentwickeln/lernen Probleme zu lösen für die sie nicht trainiert wurde | Kann nur das Problem lösen, für das sie trainiert wurde; kann sich jedoch in ihrem Gebiet spezalisieren |
| Fiktional | Existiert Tatsächlich |
¶ Wie lernt KI?
- Beim Training werden dem KI-Modell viele Beispiele der zu bewältigenden Aufgabe gezeigt und die KI versucht bei jedem dieser Beispiele eine möglichst gute Lösung zu finden
- Bei jedem neuen Beispiel wird anhand einer Kostenfunktion ermittelt, wie gut die KI die jeweilige Aufgabe bewältig hat.
- Nach dem Training wird eine KI getestet, hierfür werden Daten verwendet, die die KI zuvor im Training nicht gesehen hat, um herauszufinden, ob sie wirklich gelernt hat die Aufgabe zu lösen oder einfach nur die Trainingsdaten auswendig gelernt hat
| Trainingsdaten | Testdaten |
|---|---|
| Dienen dem Antrainieren einer KI | Zum Testen der KI |
| Haben Features: Datenwerte | |
| Haben Labels: "Oberkategorien" zu denen Features zugeordnet werden |
¶ Supervised, Unsupervised und Reinforcement Learning
Quelle für Arten machinellen Lernens: https://computingeducation.de/proj-ml-uebersicht/
- Beim Supervised (Überwachten) Lernen, wird der KI zu Training ein Datensatz gegeben, der bereits mit Labels versehen wurde
- Erfolg hängt wesentlich von Trainingsdaten ab
- Anwendung z.B. Klassifikation (Texterkennung, Objekterkennung), Prognose (Wetterprognose, Umsatzprognose)
- Beim Unsupervised (Unüberwachten) Lernen, wir der KI ein Datensatz übergeben, dem noch keine Labels hinzugefügt wurden
- Die KI muss selber ein Muster im Datensatz erkennen
- Ziel offen --> finden von Mustern/Auffälligkeiten
- Beim Reinforcement Learning (Verstärktes Lernen) ist es das Ziel, eine Policy zu finden, sodass der Agent den größtmöglichen Reward erzielt.
- Die Policy ist eine Funktion, die uns zu jeder Situation sagt, welche Aktion ausgeführt werden soll.
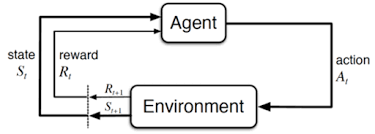
- Die Policy ist eine Funktion, die uns zu jeder Situation sagt, welche Aktion ausgeführt werden soll.
¶ Klassifizierung und Regression
Klassifizierung und Regression liegen verschiedenen Modellen der Lösungsfindung von KI zur Grundlage.
| Klassifikation | Regression |
|---|---|
| KI versucht Label vorherzusagen | KI versucht einen möglichst genauen Zahlenwert zu schätzen |
| Verwendet diskrete Variablen | Verwendet kontinuierliche Variablen |
¶ Bibliotheken
¶ Numpy
Wird hauptsächlich für wissenschaftliches Rechnen und Datenverarbeitung verwendet. Numpy bietet Unterstützung für große, mehrdimensionale Arrays und Matrizen sowie mathematischen Funktionen.
Funktionen:
- Arrays (np.array)
- Mathematische Operationen
- Zufallszahlen
¶ Matplotlib
Ermöglicht die Visualisierung von Grafiken und Diagrammen
Funktionen:
- Plotten von Daten (in Form von Diagrammen)
- Anpassbare Grafiken (Farbe, Achsen, etc.)
¶ Scikit-learn/Sklearn
Wird für maschinelles Lernen und Modellierung genutzt. Es bietet einfache Implementierungen von Algorithmen und Tools für die Datenvorverarbeitung und Modelloptimierung
Funktionen:
- Training und Evaluierung von ML-Modellen (Klassifikation, Regression, Clustering)
- Datenvorverarbeitung (Skalierung, Kodierung)
- Modellvalidierung (Cross-Validation)
- Hyperparameter - tuning (Grid Search)
¶ Pandas
Zentral erstellt für Datenanalyse und vereinfacht das Arbeiten mit Daten durch "relations" und "labels"
Funktionen:
- einlesen/exporieren von csv, excel, json, sql Datein
- erstellen und bearbeiten von Datenstruckturen (z. B.: Tabellen)